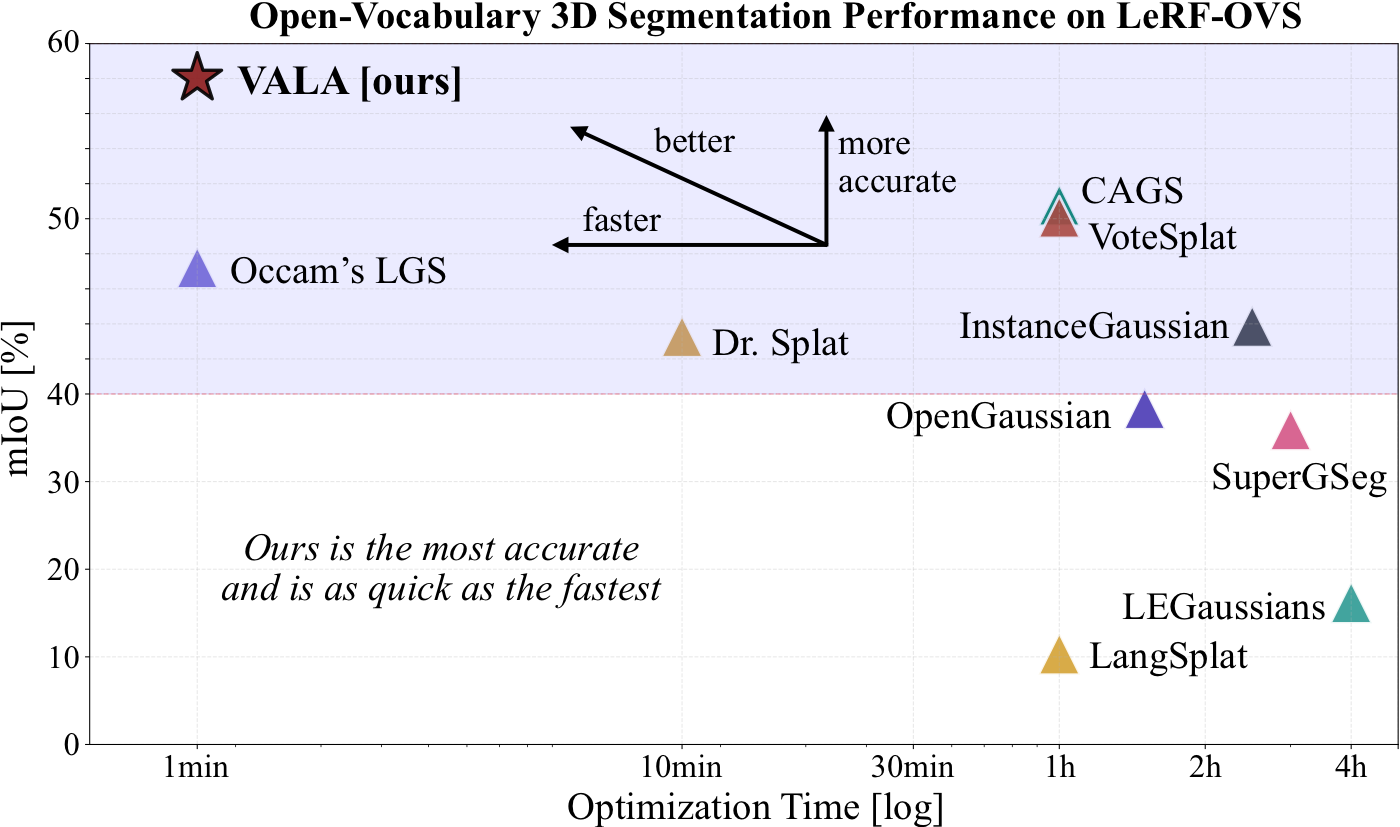
Abstract
Recently, distilling open-vocabulary language features from 2D images into 3D Gaussians has attracted significant attention. Although existing methods achieve impressive language-based interactions of 3D scenes, we observe two fundamental issues: background Gaussians contributing negligibly to a rendered pixel get the same feature as the dominant foreground ones, and multi-view inconsistencies due to view-specific noise in language embeddings. We introduce Visibility-Aware Language Aggregation (VALA), a lightweight yet effective method that computes marginal contributions for each ray and applies a visibility-aware gate to retain only visible Gaussians. Moreover, we propose a streaming weighted geometric median in cosine space to merge noisy multi-view features. Our method yields a robust, view-consistent language feature embedding in a fast and memory-efficient manner. VALA improves open-vocabulary localization and segmentation across reference datasets, consistently surpassing existing works.
Method Overview
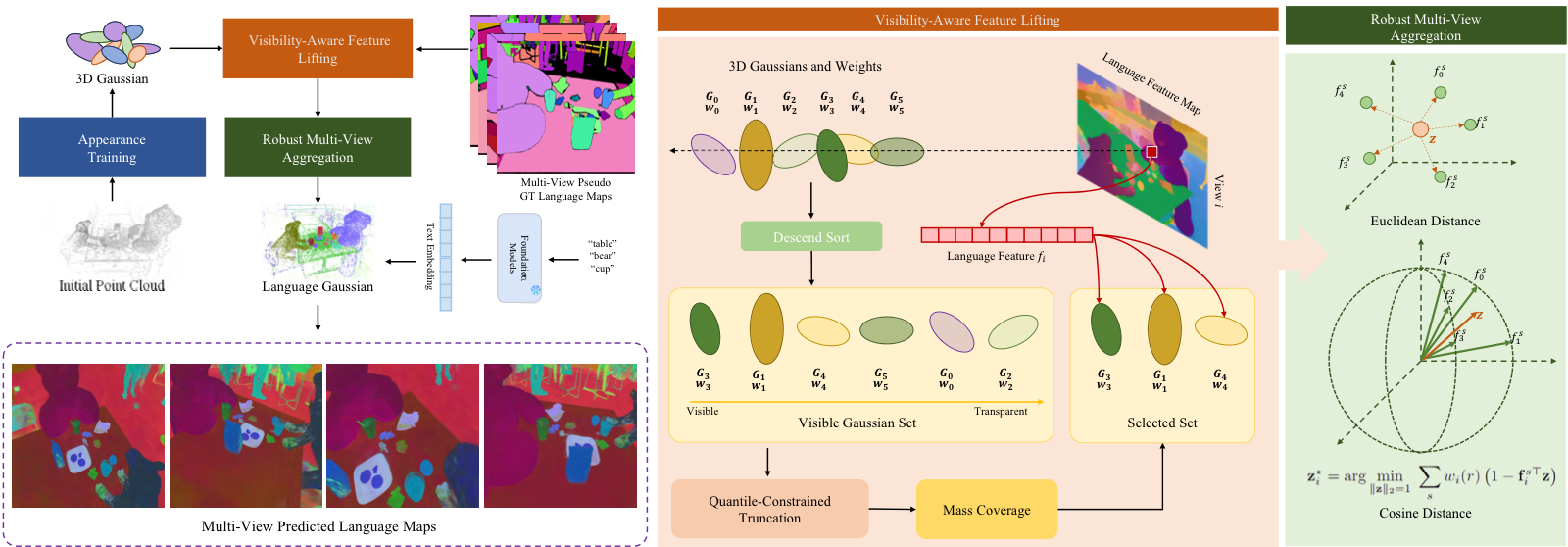
Overview of VALA. We compute per-ray marginal contributions to obtain visibility-aware gating, and aggregate multi-view language features with a streaming cosine geometric median to reduce view-specific noise and improve cross-view consistency.
Visibility-aware Gating
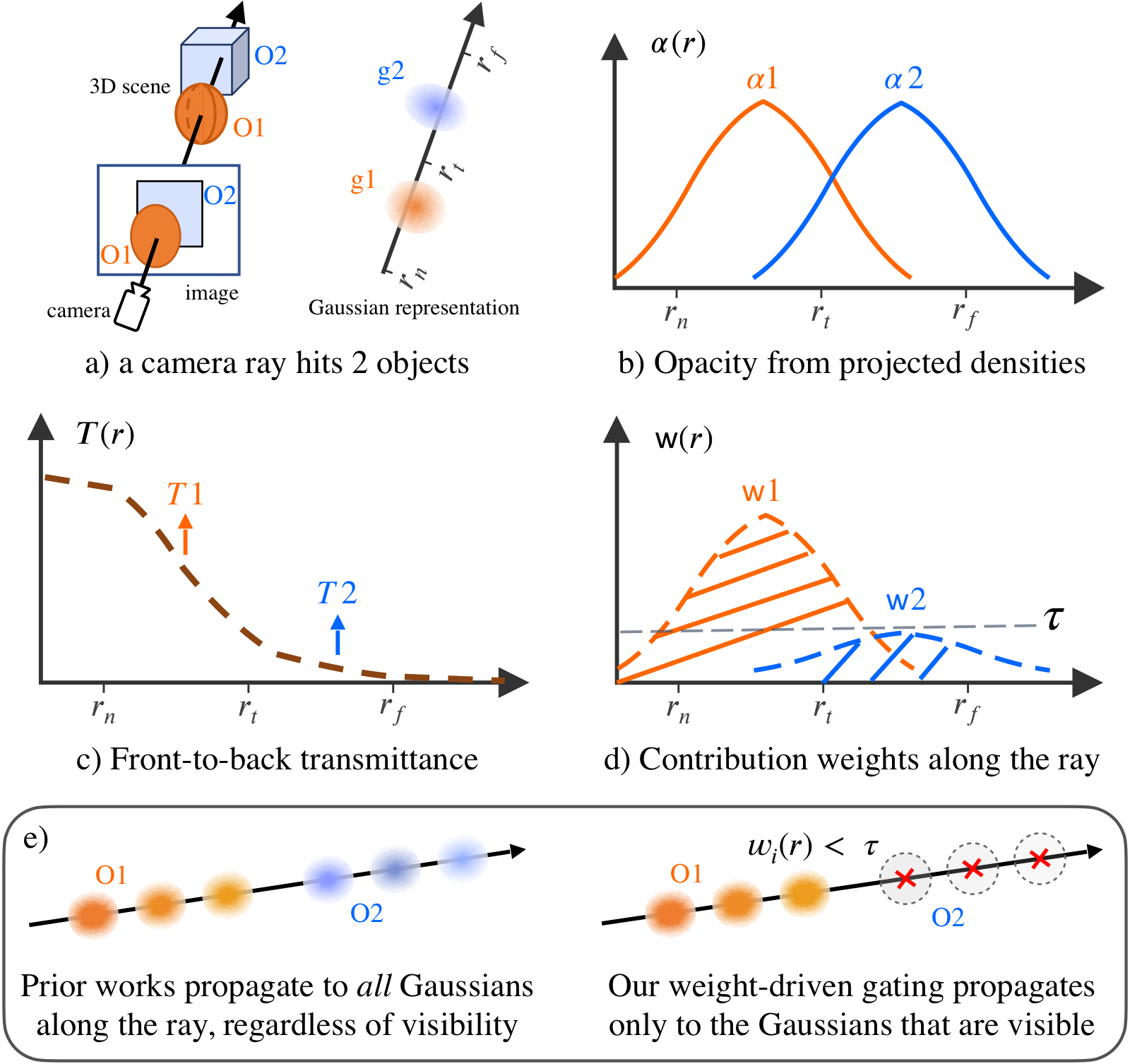
VALA retains only visible Gaussians when propagating 2D language features, preventing background Gaussians (with negligible contribution) from inheriting foreground semantics.
Results
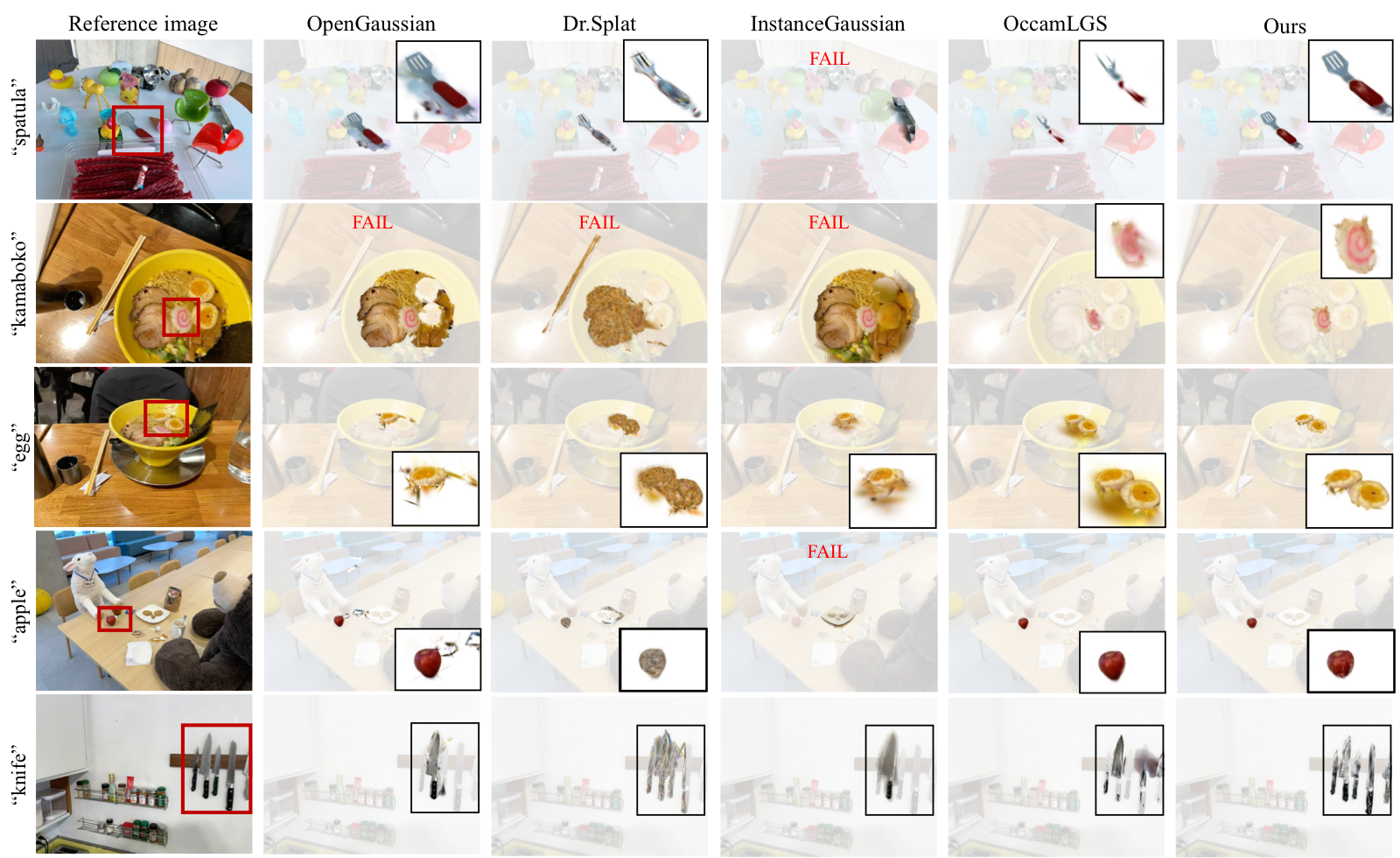
Qualitative results on LeRF-OVS.
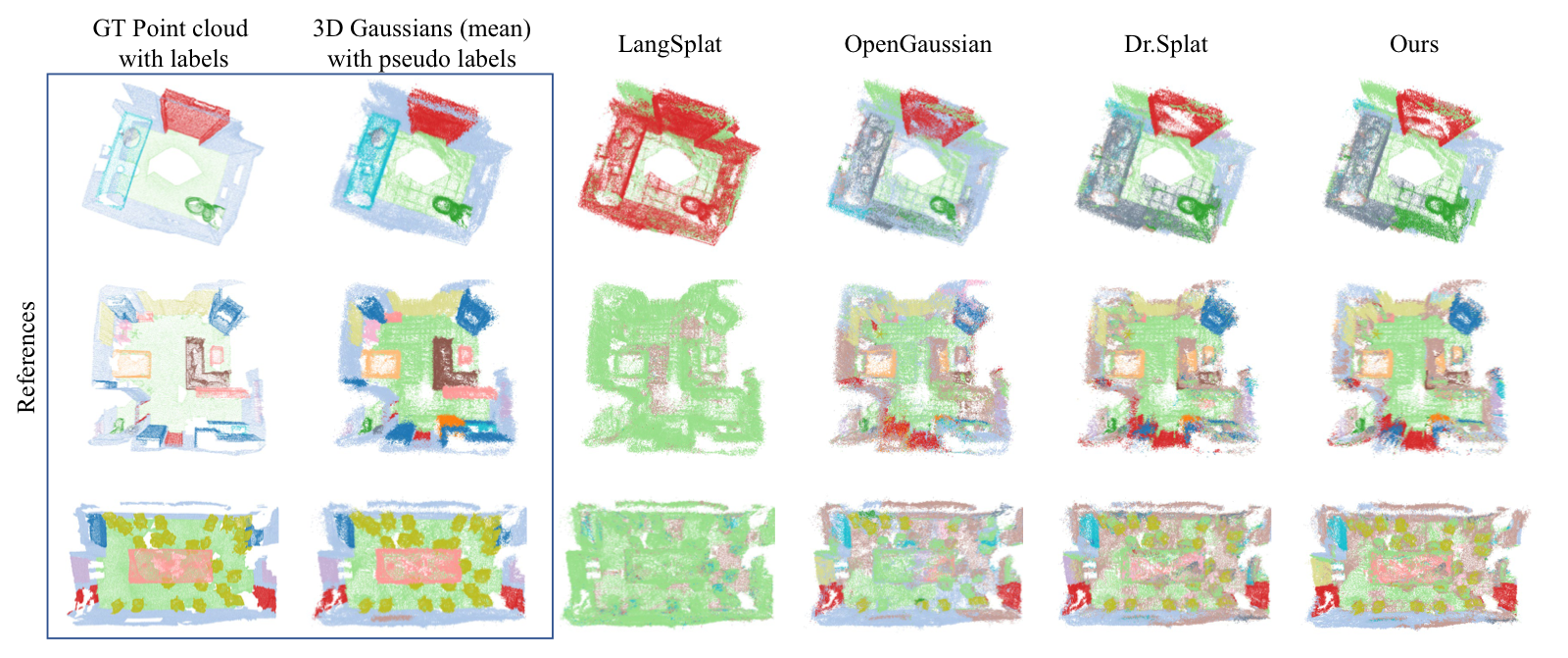
Qualitative results on ScanNet.

Supplementary qualitative results on an outdoor dataset (Waymo).
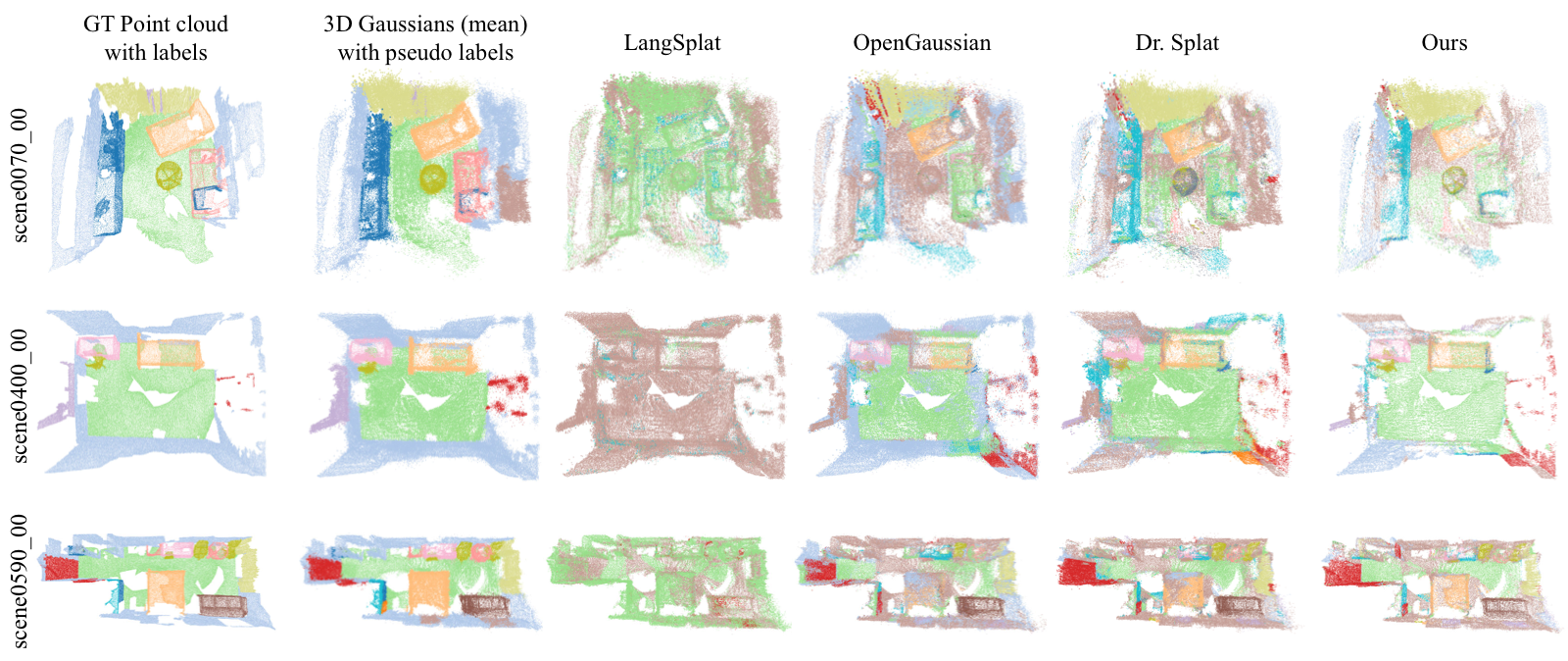
Supplementary qualitative results on ScanNet.
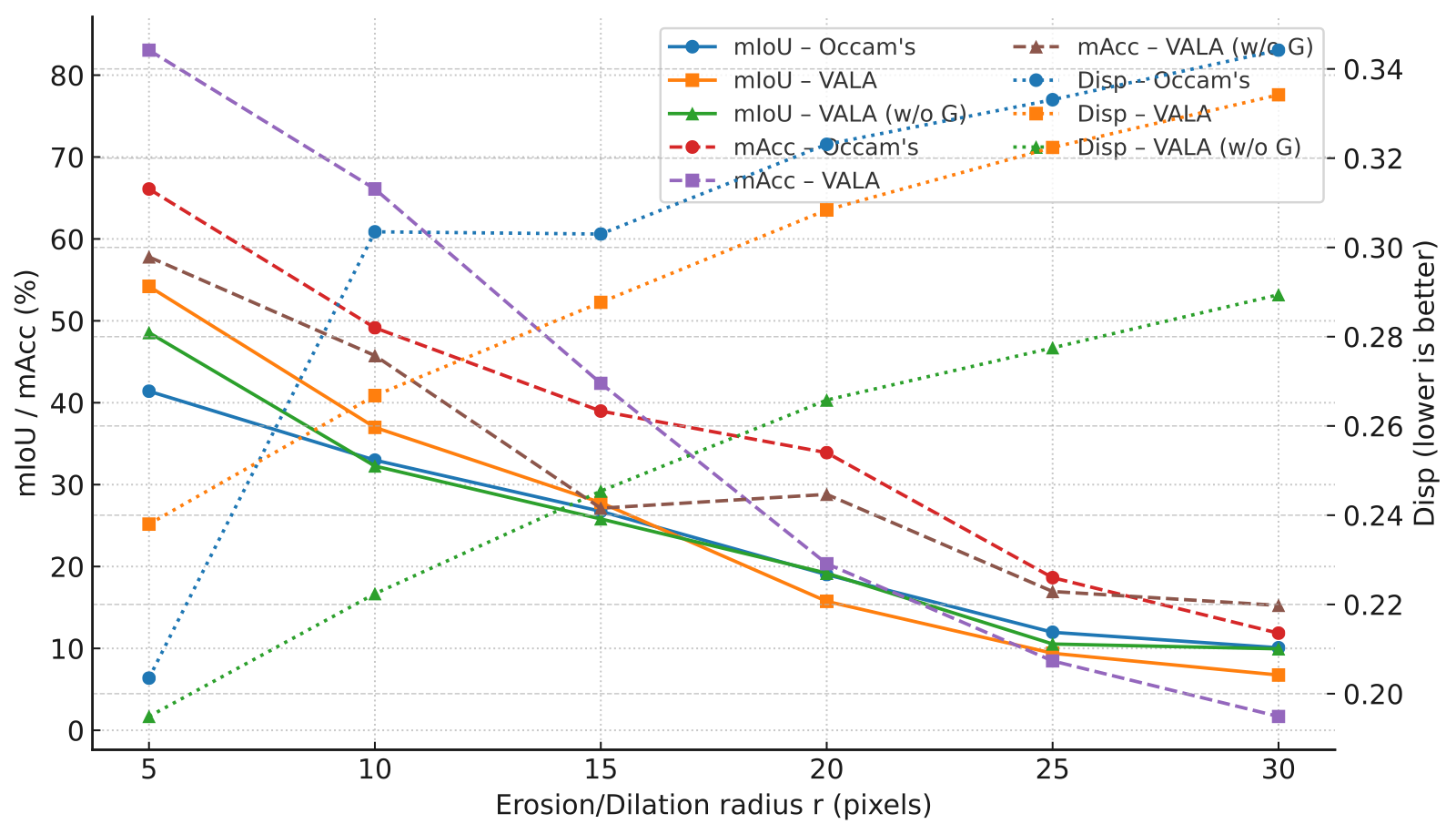
Robustness under mask boundary corruptions. mIoU/mAcc (%) are shown on the left y-axis; Disp (lower is better) on the right y-axis. We vary the erosion/dilation radius r (pixels). VALA degrades more slowly than Occam’s and its ablation without gating (VALA w/o G), while achieving lower Disp across severities.
BibTeX
@misc{wang2025vala,
title={Visibility-Aware Language Aggregation for Open-Vocabulary Segmentation in 3D Gaussian Splatting},
author={Sen Wang and Kunyi Li and Siyun Liang and Elena Alegret and Jing Ma and Nassir Navab and Stefano Gasperini},
year={2025},
eprint={2509.05515},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.05515}
}